
Paper link | Note link | ICML 2023
這項研究提出了首個檢索增強的多模態模型,能夠檢索和生成文本和圖像。
它可以應用於各種下游任務,例如圖像生成、文本轉圖像、圖像轉文本等。
與 DALL-E 和 CM3 等多模態模型不同,這項研究並未將所有知識存儲在模型參數中。
相反,它提出了一種檢索增強的多模態模型。
這種方法允許基礎多模態模型(generator)訪問由 retriever 從外部記憶源獲取的相關文本和圖像。
多模態模型可以執行如從文本生成圖像、從圖像生成文本,甚至同時生成文本和圖像等任務。
這些模型大多需要大量的參數來儲存它們的知識。
最近,檢索增強語言模型(RAG)在自然語言處理(NLP)領域顯示了潛力。
給定輸入文本,RAG 模型使用 retriever 從外部記憶中獲取相關文檔,並使用 generator 根據檢索到的文檔生成預測。
作者提出一個問題,我們能否將RAG框架應用於多模態模型?
這項研究提出了首個檢索增強的多模態模型,能夠檢索和生成文本與圖像。

這項研究使用 CM3 Transformer 架構來構建 RAG 模型。
這是一種為多模態文檔設計的 Transformer decoder 模型。
具體而言,CM3將每個多模態文檔格式化為HTML序列,如 <img alt=[text] src=[image]>,其中 [text] 是文本標記序列,而 [image] 是由圖像標記器獲得的圖像標記序列。

Retriever  接收一個查詢
接收一個查詢 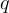 和來自記憶
和來自記憶 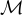 的候選文檔
的候選文檔 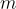 ,並返回一個相關性分數
,並返回一個相關性分數 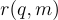 。
。
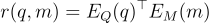
其中 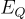 和
和 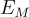 是查詢和記憶文檔的 encoder。
是查詢和記憶文檔的 encoder。
在這項研究中, 和 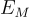 用於編碼文本和圖像內容。CLIP 被用來實現這些 encoder。
用於編碼文本和圖像內容。CLIP 被用來實現這些 encoder。
為了確定相關性分數,他們使用 maximum inner product search,然後從這個列表中抽取最終的 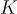 個檢索文檔。
個檢索文檔。
本研究使用CM3作為基礎模型。
CM3同時接收輸入序列 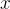 和結果序列
和結果序列  。
。
為了訓練 generator,他們優化以下損失函數:
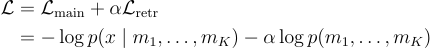
這項研究使用了LAION作為外部知識。
他們測試了幾個任務,例如:
標題到圖像生成在MS-COCO上的表現:

圖像到標題生成在MS-COCO上的表現:

可控圖像生成的示例案例:

圖像編輯的示例案例:


 iThome鐵人賽
iThome鐵人賽